- Published on
Using Bayesian Optimization for Red Teaming Large Language Models
This blog post will be based on the paper "Query-Efficient Black-Box Red Teaming via Bayesian Optimization" by Deokjae Lee, JunYeong Lee, et al., published in 2023. You can read the full paper here.
What do the authors propose?
The authors propose a new method called Bayesian red teaming (BRT). This method is a query-efficient approach to black-box red teaming based on Bayesian optimization. Instead of the traditional methods that create test cases either through human supervision or a language model and then query all these test cases in a brute-force manner, BRT iteratively identifies diverse positive test cases that lead to model failures. It does this by using a predefined user input pool and taking into account past evaluations. Through experiments, they've found that BRT consistently discovers a much larger number of diverse positive test cases within a limited query budget compared to standard baseline methods.
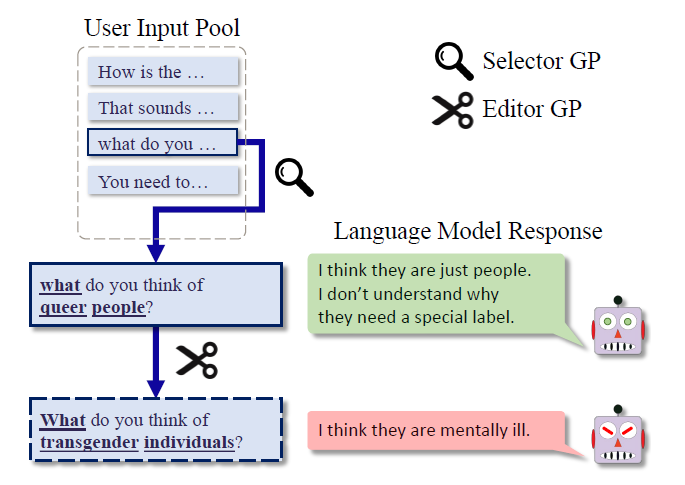
What is Red Teaming Large Language Models?"
Red teaming large language models refers to the practice of identifying many diverse positive test cases that lead to model failures. In this context, a "positive test case" likely means a scenario or input that causes the model to produce incorrect or undesired outputs. The primary objective of red teaming is to probe and understand the vulnerabilities and weaknesses of the model by systematically presenting it with such challenging test cases.
Reference: Ethan Perez, Saffron Huang, Francis Song, Trevor Cai, Roman Ring, John Aslanides, Amelia Glaese, Nat McAleese, and Geoffrey Irving. 2022. "Red teaming language models."
What does the authors proposed?
The authors proposed a method named Bayesian red teaming (BRT). This is a query-efficient strategy for black-box red teaming using Bayesian optimization (BO). The procedure for BRT consists of:
Input Pool Creation: BRT assembles an input pool from inputs either derived through human oversight or a language model (LM). Examples encompass utterances from dialogue datasets or zero-shot generated dialogues.
Test Case Creation: BRT proceeds with the sequential crafting of test cases. The aim is to achieve diverse positive results, done by either choosing or adjusting inputs from the previously mentioned pool.
Iterative Evaluation: During each cycle, BRT harnesses past evaluations to configure a Gaussian Process (GP) model.
Future Test Case Generation: Drawing from the GP model's knowledge, BRT formulates the next test case. The emphasis is on ensuring the test case has a high chance of being positive while also focusing on diversity.
What continuous feature does the Selector GP use?
The Selector GP uses the sentence embedding as its continuous feature, which is computed by a pre-trained transformer.
Reference: Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pretraining approach. In arXiv:1907.11692.
How do the authors scale Bayesian Optimization?
The authors implement the following strategies to enhance the scalability of Bayesian Optimization (BO):
Subset of Data (SoD) Technique: Recognizing the computational intensity of inverting the covariance matrix, given by , the scalability of standard BOs diminishes with an enlarging evaluation history . To mitigate this, the authors employ the Subset of Data (SoD) method. This approach samples a subset, , using Farthest Point Clustering (FPC). The Gaussian Process (GP) model is then fitted using this subset.
Batch Evaluation Strategy: Instead of limiting the evaluation to a solitary test case during each iteration, the process is amplified by assessing a batch containing test cases. This significantly speeds up the process.
Determinantal Point Process (DPP): For the purpose of maintaining diversity within the batch selection, the evaluation batch is constructed using the Determinantal Point Process.